RTO y RPO: Estrategias de Continuidad para Líderes de TI
Domine las métricas clave de recuperación. Aprenda a definir tiempos de inactividad tolerables y pérdida de datos para proteger su operación crítica.

El Costo del Silencio: Por qué el RTO y RPO son Decisiones de Negocio, no solo de TI
En el ecosistema de infraestructura crítica, la interrupción de un servicio no se mide solo en minutos, sino en impacto financiero, reputacional y legal. Muchos directivos cometen el error de delegar la continuidad operativa exclusivamente a los scripts de respaldo.
Sin embargo, sin una definición clara del Recovery Time Objective (RTO) y el Recovery Point Objective (RPO), cualquier solución de backup o replicación es simplemente una apuesta. El verdadero reto del CTO moderno es alinear la capacidad técnica de la infraestructura con las expectativas de supervivencia de la organización.
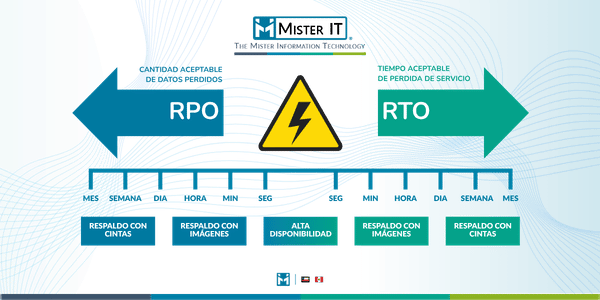
- RPO (Recovery Point Objective): La Tolerancia a la Pérdida de Datos
El RPO define el volumen de datos que la empresa está dispuesta a perder, medido en tiempo desde el último backup o réplica hasta el momento del incidente. Es una métrica de integridad y frecuencia.
Arquitectura de Datos: Para sistemas transaccionales de alta intensidad (Bases de Datos, ERP), un RPO cercano a cero requiere tecnologías de Replicación Sincrónica.
Impacto Técnico: Si su RPO es de 4 horas, pero su backup ocurre cada 12, existe una brecha de vulnerabilidad crítica de 8 horas.
Mejores Prácticas: Implementar políticas de Snapshotting y CDPs (Continuous Data Protection) para reducir el RPO sin penalizar el rendimiento del almacenamiento (I/O).
- RTO (Recovery Time Objective): El Cronómetro de la Recuperación
Mientras el RPO mira hacia atrás, el RTO mira hacia adelante. Representa el tiempo máximo permitido para que un servicio vuelva a estar en línea después de una caída. Es una métrica de capacidad y velocidad.
Variables de Recuperación: El RTO incluye la detección del fallo, la provisión de infraestructura (On-premise o Cloud), la restauración de datos y las pruebas de consistencia.
Alta Disponibilidad (HA): Lograr un RTO de minutos exige configuraciones de Failover Automático y arquitecturas de redundancia activa-activa.
El Factor Humano: Un RTO ambicioso no solo depende de hardware; requiere Playbooks de Disaster Recovery (DRP) probados y automatizados para eliminar el error manual bajo presión.
- El Equilibrio entre Costo y Disponibilidad: Tiering de Servicios
No toda la carga de trabajo requiere el mismo nivel de inversión. Una estrategia de DR (Disaster Recovery) eficiente segmenta los servicios según su criticidad:
Misión Crítica: RTO < 1 hora, RPO = 0. Requiere Hot Sites y replicación en tiempo real.
Operativo Importante: RTO < 4 horas, RPO < 1 hora. Uso de réplicas asíncronas y Warm Sites.
Soporte/Legacy: RTO 24-48 horas, RPO 24 horas. Restauración desde backups tradicionales o Cloud Tiering de bajo costo.
Conclusión: Resiliencia por Diseño
Definir el RTO y RPO no es un ejercicio teórico; es la base de la arquitectura de resiliencia de su empresa. Un desfase entre lo que el negocio espera y lo que el departamento de TI puede entregar es la principal causa de crisis corporativas durante desastres tecnológicos. En Mister IT, transformamos estas métricas en infraestructuras robustas capaces de resistir y recuperarse ante cualquier escenario.
¿Su infraestructura actual garantiza los SLAs que su negocio exige? En Mister IT, actuamos como su brazo de ingeniería especializado para diseñar y auditar planes de continuidad operativa que realmente funcionan.